缘起
在现在的自然语言处理(Natural Language Processing) 中,一个句子通常是被看成一系列词语的全排列,这些词语能够形成各种不同的组合状态,比如:
- 我 在 北京 天安门
- 在 我 北京 天安门
- 北京 我 在 天安门
- 北京 在 我 天安门
- ...
在这些所有可能的排列的情况中,只有很少一部分(由于语言的多样性,不一定只有一种可能是合法)是可以被人理解的,那么该如何衡量一个词语序列是否是可被理解,或者说怎样的词语序列是合法的?自然语言处理大师贾里尼克(Fred Jelinek)1帮我们给出了答案,他用一个非常漂亮的统计数学模型来描述一个自然语言的句子,从而解决了上面的疑问,而这个模型就是本文的主角语言模型(Language Model)。
语言模型在自然语言处理的各项任务中占有极其重要的地位,尤其在基于统计模型的语音识别、机器翻译、句法分析、短语识别、词性标注、手写体识别和拼写纠错等相关研究中得到了广泛应用。
语言模型
概率表示
其实,贾里尼克给出的方法是非常简单的,他给每一个句子赋予一个概率,合法的句子得到概率比较大,而不合法的句子得到的概率比较小,这样只需要从所有可能的情况中选取概率最大的那种组合,我们就能够得到合法的句子了。那么这个概率该如何赋予呢?如何保证合法的就能够得到大概率,不合法的就是小概率呢?这就需要我们从数学角度来看待这个问题了。
假设\(S\)表示一个有意义(合法)的句子,我们可以将其表示成\(S=w_1,w_2,\cdots,w_n\),其中\(w_i\)表示第\(i\)个词语。用\(P(S)\)来表示这个句子出现的概率,那么根据我们就可以做一下简单的展开:
利用简单条件概率公式,我们可以进行如下的推导:
其中\(P(w_1)\)表示第一个词语是\(w_1\)的概率,\(P(w_2\vert w_1)\)表示在给定第一个词\(w_1\)的情况下,\(w_2\)出现的概率,后面的以此类推。其实可以看到,第\(i\)个词语出现的概率是由其前面的\(i-1\)个单词所决定的。
从计算角度来说,\(P(w_1)\)和\(P(w_2\vert w_1)\)比较容易计算的,但是\(P(w_3\vert w_1,w_2)\)就会变得比较难计算,因为它已经涉及到了3个变量,再往后的话,需要考虑的变量个数将越来越多,会变得复杂无比,难以计算。
马尔科夫假设
为了解决太过复杂而难以计算的问题,我们需要引入马尔科夫假设,马尔科夫假设中最重要的一点就是有限视野假设,也就是说,每一个状态只和它前面的\(n-1\)个状态有关,这被称为n阶马尔科夫链。当应用在我们的语言模型中时,就是指每一个词语的概率只由其前面的\(n-1\)个词语所决定,这被称为\(n\)元语言模型。 当\(n=2\)时,相应的语言模型就被称为是二元模型,以二元模型为例,我们可以将上面的展开式改写成:
经过马尔科夫假设的简化,在二元模型中,我们每次只需要考虑两个变量,而在三元模型中,我们每次只需要考虑3个变量,变量越少,计算越是简便,当然这也说明模型简单,不能很好地模拟实际情况。
其实这也是一个需要平衡的过程,n越大越能反映出真实的分布情况,但是相应地也带来很大的计算代价;n越小,虽然计算方便,但是模型就越简单,不能很好的反映出实际的概率分布。
目前来说,最常用是的二元、三元模型,而google的翻译系统使用的是五元模型2,这在《Beautiful Data》的第十四章中有所论述,有兴趣的朋友可以去看看。
概率估计
到目前为止,我们知道了:
- 一个句子可以看成是一系列词语的全排列
- 每一种排列情况都能够通过条件概率公式计算得到一个表示这个句子合理性的概率
- 通过引入马尔科夫假设,简化了句子概率的计算过程。
现在的问题是,如何估计这些词语出现的概率呢?以二元语言模型为例,我们如何获得\(P(w_i\vert w_{i-1})\)呢?从概率统计中我们知道,\(P(w_i\vert w_{i-1}) = \frac{P(w_i,w_{i-1})}{P(w_{i-1})}\)
这就为我们计算\(P(w_i\vert w_{i-1})\)提供了一种方法,在拥有大语料的情况下,我们可以直接统计\((w_{i-1},w_i)\)这对词在语料中的出现次数,同时也能统计\(w_{i-1}\)出现的次数,这样当语料库足够大时,根据大数定理,相对频度就能近似概率,也即:
其中\( \#(x_{i-1},x_i), \#w_{i-1}, \#\)分别表示词对\((w_{i-1},w_i)\)在语料中出现的次数,\(w_{i-1}\)在语料中出现的次数和语料库的大小。
模型训练&零概率
语言模型中需要知道的所有的条件概率,我们称之为模型的参数,从语料中获得这些概率的过程就是模型学习的过程。
根据上一节所说的内容,训练的过程其实就是在语料库中统计词频的过程,但是也去会出现这样的情况:\(\#(x_{i-1},x_i)=0\),即两个词语同现的次数为0,那根据我们的计算就应该是\(P(w_i\vert w_{i-1})=0\),反过来,如果\(\#(w_{i-1},w_i)\)和\(\#w_{i-1}\)都只出现了一次,那么\(P(w_i\vert w_{i-1})=1\),这显然是不合理的。
概率值出现为0的这种情况我们称之为不平滑,相应的需要进行平滑操作.
事实上,自然语言处理方向上的各位前驱学者已经为我们设计了很多的平滑方法,主要包括有:
- 加法平滑
- 古德-图灵(Good-Turing)估计法
- Katz平滑方法
- Jelinek-Mercer平滑方法
- Witten-Bell平滑方法
- 绝对减值法
- Kneser-Ney平滑方法
鉴于上述的这些方法我也不是全部都能理解,这里只能对最简单的加法平滑做一下简单的介绍。
加法平滑的思想其实是非常简单的,它假设每一个词对/词都至少在语料中出现过\(\lambda\)次,这样就能避免出现零概率的情况了。还是用二元语言模型来举例,经过平滑后的计算公式就变为:
其中,\(\vert V \vert\)表示词库的大小,之所以要在分母上同时加上一个\(\lambda\vert V\vert\),是为了保证概率之和为1的条件.
在实际使用中,\(\lambda\)通常取为1.
具体实现
#!python
#coding:utf-8
"""
Program: 语言模型的简单实现
Description: 简单实现一个N元的语言模型,其中N是可以进行设置的参数.
Author: Flyaway - flyaway1217@gmail.com
Date: 2014-01-16 19:23:29
Last modified: 2014-01-16 21:54:08
Python release: 3.2.3
"""
import math
class LM:
def __init__(self,train_path,step=2,lam=1):
#punctuations need to be removed
self.punctuation = set([",","、","。","?","“","”","!",";","‘","’","《","》","%"])
self.step = step
self.lam = lam
self.words = []
self.freq = {}
#read the train data and remove the punctuation
with open(train_path) as f:
unique = set()
for line in f:
s = line.strip().split()
#remove the punctuation
s = [item.strip() for item in s if item not in self.punctuation]
#gather the unique word
for r in s:
unique.add(r)
#add the start/end symbol
s.insert(0,'<s>')
s.append('</s>')
self.words.append(s)
self.size = len(unique)
def getNgram(self,sentence):
for e in range(1,len(sentence)-1):
if e > self.step: s = e - self.step + 1
else: s = 0
words = sentence[s:e+1]
words.insert(-1,'|')
words = ','.join(words)
words = words.replace(',|,','|')
yield words
def train(self):
for sentence in self.words:
for words in self.getNgram(sentence):
s = words.split('|')
cond = s[0]
w = s[1]
if cond not in self.freq:
self.freq[cond]={}
self.freq[cond][w] = 1
else:
self.freq[cond][w] = self.freq[cond].get(w,0) + 1
def getProb(self,word,condition):
cond = condition
cond_num = 0
w_num = 0
if cond in self.freq:
for key in self.freq[cond]:
cond_num += self.freq[cond][key]
w_num = self.freq[cond].get(word,0)
#smooth
w_num = w_num + self.lam
cond_num += (self.size * self.lam)
return float(w_num/cond_num)
def sentenceProb(self,sentence):
mysentence = sentence.strip().split()
mysentence.insert(0,'<s>')
mysentence.append('</s>')
result = 0
for words in self.getNgram(mysentence):
s = words.split('|')
cond = s[0]
w = s[1]
result += math.log(self.getProb(w,cond),2)
return result
if __name__ == '__main__':
inpath = './Data/train.in'
print('Reading data...')
lm = LM(inpath,2)
print('Start training...')
lm.train()
s1 = '我 在 北京 天安门'
s2 = '在 我 北京 天安门'
s3 = '北京 我 在 天安门'
s4 = '北京 在 我 天安门'
for s in [s1,s2,s3,s4]:
print(s,end=":")
print(lm.sentenceProb(s))
上述代码的运行结果如下图所示:
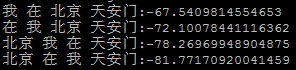
二元模型:
三元模型:
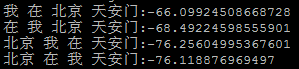
从结果中就可以看到,正确的句子得到的值总是最大的,这就说明了语言模型的强大威力。
需要注意的是,这里的输出值并不是其相应的概率,从代码中可以看到,我使用了一个math.log对数函数,这是因为如果直接用概率连乘计算的话,概率值会变得非常小,很容易就会造成溢出,因此这里使用了对数函数,将连乘变成了累加,避免了溢出的情况,同时由于对数函数的单调性,所以概率值的相对大小是不会改变的,这也算是一个技巧吧。
参考资料
- 《统计自然语言处理》宗成庆
- 我爱自然语言处理
- 《数学之美》吴军
Comments
So what do you think? Did I miss something? Is any part unclear? Leave your comments below